Overview of datasets
| Dataset | Class Type | Size | Annotation Type | Format | Balanced | Counterfactual |
|---|---|---|---|---|---|---|
| Gender Classification |
Binary | 5,000 | Human annotation | Pixel-wise | Yes | Yes |
| Scene Recognition |
Binary | 5,000 | Human annotation | Pixel-wise | Yes | Yes |
| Face Glasses Recognition |
Binary | 2,614 | Human annotation | Pixel-wise | Yes | No |
| Prohibited Item Detection |
Binary | 17,654 | Human annotation | Bounding-box | Yes | No |
| Nodule Detection |
Binary | 5,250 | Human annotation | Pixel-wise | Yes | No |
| Tumor Detection |
Binary | 361 | Human annotation | Pixel-wise | No | No |
| Cats and Dogs Classification |
Binary | 7,390 | Foreground extraction | Pixel-wise | No | No |
| Object Classification |
Multi-class | 4,318 | Foreground extraction | Pixel-wise | No | No |
Gender Classification (Gender-XAI)

| Download |
The gender classification task utilized in our study is derived from the Microsoft COCO dataset. To construct the task-specific dataset, we extracted images from the COCO dataset that contained captions with the terms “men” or “women”. Further filtering was performed to remove images that mentioned both genders in the caption, depicted multiple individuals, or featured unrecognizable human figures. Additionally, a subset of the images underwent manual annotation by human annotators using human annotation user interfaces (UIs), resulting in factual and counterfactual masks. The dataset comprises a total of 1,736 images, each with a class label and human explanation annotation, evenly distributed between females and males.
Scene Recognition (Scene-XAI)

| Download |
The scene recognition dataset used in our study is derived from the Places365 dataset. The dataset was further annotated manually by Gao et al. with human annotation UIs to obtain factual and counterfactual masks. The task of this dataset involves binary classification for scene recognition, specifically distinguishing between nature and urban scenes. To create the dataset, we selectively sampled images from specific categories. Specifically, the categories used to sample the data are: Nature: mountain, pond, waterfall, field wild, forest broadleaf, rainforest Urban: house, bridge, campus, tower, street, driveway In total, the dataset comprises 2,086 images, each with a class label and human explanation annotation.
Face Glasses Recognition (Glasses-XAI)

| Download |
The face glasses recognition dataset is derived from the CelebAMask-HQ dataset. The dataset is initially categorized dito stinguishing face images with and without glasses. The CelebAMask-HQ dataset includes manually annotated masks with 19 classes covering various facial components and accessories. We utilized the segmentation masks of eyes and glasses to derive factual labels for glasses recognition. The dataset includes 885 images, each with a class label and corresponding human explanation annotations.
Prohibited Item Detection (Prohibited-XAI)

| Download |
The prohibited item detection task in our study is constructed using the Sixray dataset. The dataset is partitioned by categorizing images based on the presence of prohibited items. The Sixray dataset, partitioned based on the recognition of prohibited items, comprises an extensive suite of 1,059,231 X-ray images. Each image is annotated at the image level by experienced security inspectors, repurposed as human explanation annotations. This approach capitalizes on professional insight, ensuring that our dataset’s annotations reflect real-world classification scenarios and provide a reliable basis for the binary classification of prohibited items. Consequently, each image is labeled with both a class label and a corresponding ground-truth explanation annotation.
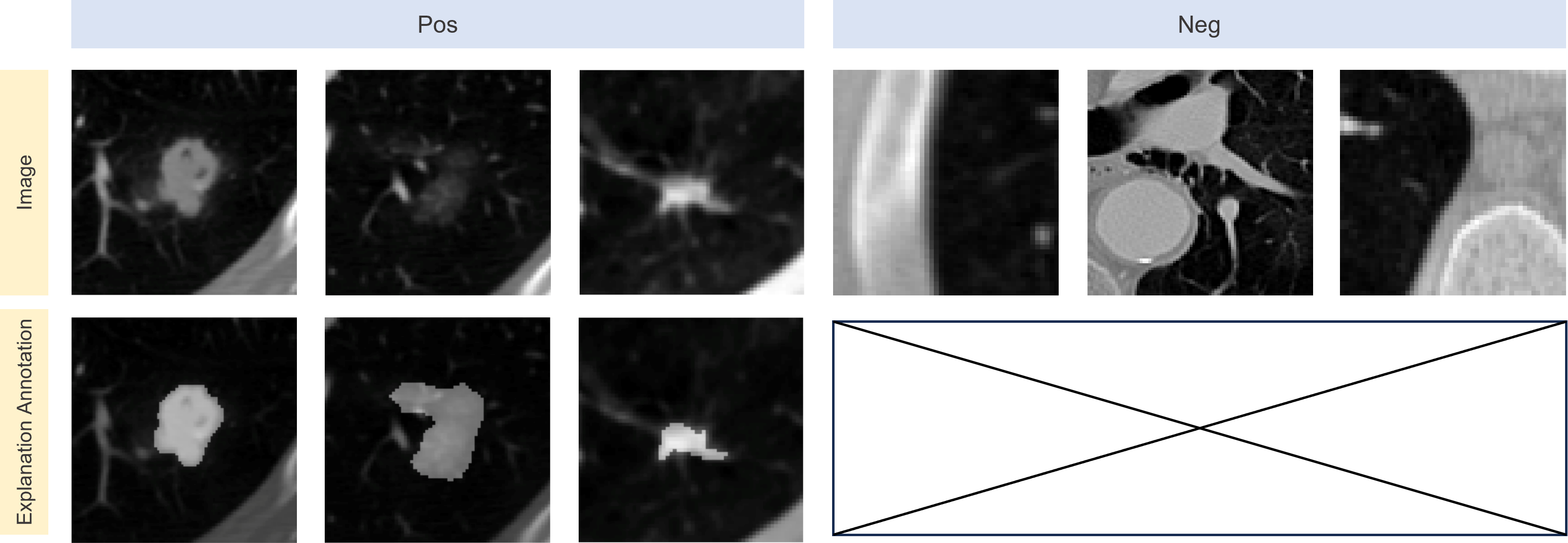
Nodule Detection (Nodule-XAI)
| Download |
We construct the nodule detection dataset from LIDC-IDRI
which comprises thoracic computed tomography (CT) scans from lung cancer screenings annotated with lesion markers.
We converted the 3D nodule images into 2D by selecting the central slice along the z-axis and resizing it to 224×224 pixels.
Up to four experienced thoracic radiologists provided annotations in XML format for each scan.
The ground truth explanation was established by computing a consensus volume from these annotations, with a nodule considered positive if agreed upon by at least 50% of the radiologists.
Conversely, negative samples were derived by slicing surrounding areas without nodules.
After preprocessing, the dataset includes 2,625 positive nodule images and 65,505 negative non-nodule images.
The primary objective of utilizing this dataset is to determine the presence or absence of nodules in the images.
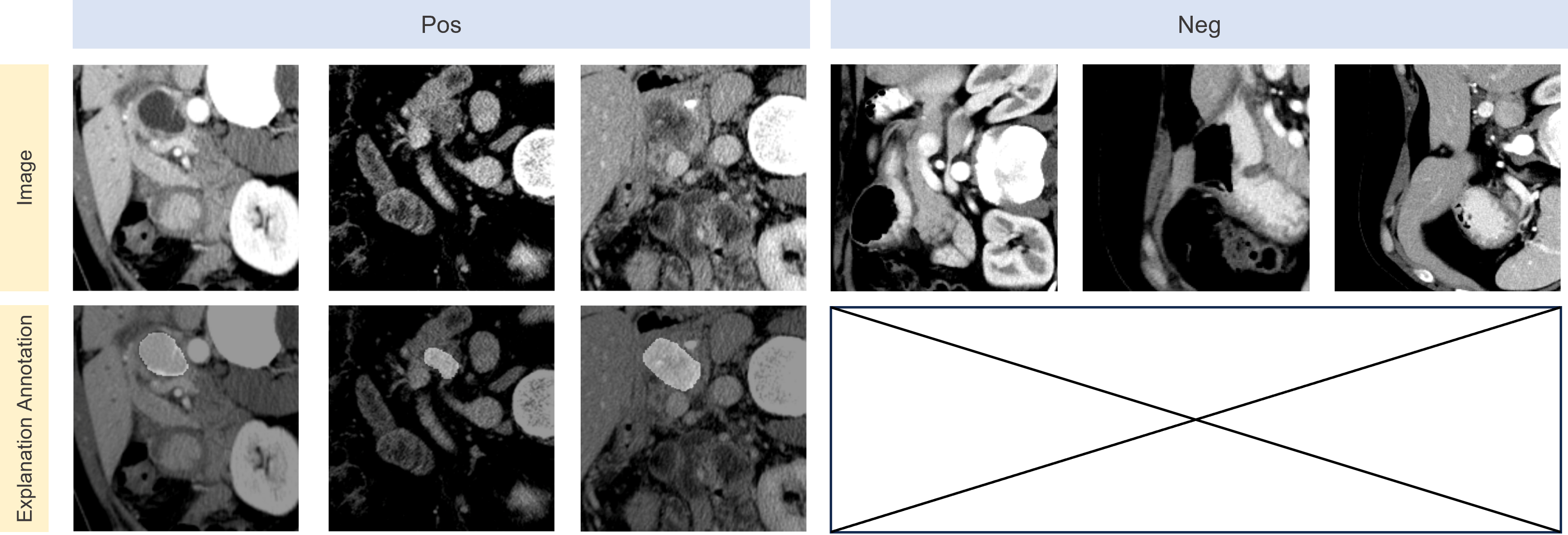
Tumor Detection (Tumor-XAI)
| Download |
To construct our dataset, we sourced normal pancreas images from the Cancer Imaging Archive. Abnormal scans, featuring pancreatic tumors, were derived from the Medical Segmentation Decathlon dataset (MSD), where initial ground-truth annotations by a medical student were rigorously reviewed and refined by a skilled radiologist. The dataset comprises a total of 281 scans with tumors and 80 scans without tumors. In a preprocessing approach akin to that used for the LIDC-IDRI dataset, we converted the 3D scans into 2D slices by randomly selecting along the z-axis, thus setting the stage for a binary classification task to discern between positive (tumorous) and negative (normal) pancreatic samples.
Cats and Dogs Classification (Cat&Dog-XAI)

| Download |
The Cats and Dogs Classification Dataset used in our study is constructed from The Oxford-IIIT Pet Dataset. This dataset, tailored for pet image analysis, contains over 7,000 images across 37 unique categories, each corresponding to different breeds of dogs or cats. For the purposes of our research, we treat pixel-level foreground extractions, which isolate the pet from the background, as proxies for human explanation annotations. These extractions effectively highlight the subject of interest in alignment with the class label, mirroring the focus areas a human annotator might identify when asked to explain the basis for classifying an image as either a dog or a cat.
Object Classification (Object-XAI)

| Download |
The Object Classification Dataset utilized in our study is constructed from the PASCAL VOC 2012 Dataset. The dataset comprises roughly 11,540 images images and covers 20 diverse object categories. These include cars, dogs, chairs, people, bicycles, cats, horses, birds, boats, aeroplanes, buses, trains, motorcycles, cows, dining tables, potted plants, sheep, sofas, TVs, and bottles. Each image within the dataset is manually annotated with pixel-level region masks and corresponding class labels for identified objects, providing a robust resource for object classification research. In our study, explanation annotations were generated by extracting the pixel-level foreground corresponding to the image label class, leveraging these precise regions as effective proxies for human explanations by directly highlighting the areas most relevant to the object’s classification.